从词到注意力:我是如何理解 Transformer 的
相关信息
这篇文章是从我之前做的 Beamer slides:From Words to Attention: The Road to the Transformer 改出来的。它不是严格的公式教程,更像是我把这条学习路线重新走了一遍:为什么我后来不再把 Transformer 只看成一个 NLP 架构,而是把它看成一种通用的依赖建模方式。
Transformer 之前的问题
讲 Transformer 很容易一上来就写这个式子:
这个式子当然重要。但对我来说,从它开始反而有点太晚了。真正卡住我的问题更朴素:
机器到底应该怎样表示一个词,才能同时保留意义、上下文和关系?
Transformer 是这个问题的一个答案,但它不是凭空出现的。它前面有一串“不太够用”的答案:one-hot 解决了身份标识,却没有相似性;N-gram 给了局部上下文,却没有抽象能力;word embedding 给了语义几何,却没有动态语境;RNN 给了状态记忆,但长距离信息还是容易丢,计算也被迫按时间一步步走。Attention 真正改变的是信息流的形状:不要把所有东西挤进一条窄窄的时间链,而是让每个位置自己去问“我现在需要看哪里?”
这就是我想从 slides 中保留下来的主线。
先从离散符号说起
最早的表示方式很干脆:每个词就是词表里的一个编号。one-hot 向量只有一个位置是 1,其余位置全是 0。
对于词表 ,词 可以表示成:
这种表示很适合查表。它清楚地告诉模型“出现的是哪个符号”。但它完全没有告诉模型“这个符号是什么意思”。如果只看 one-hot 距离,"cat" 和 "dog" 的距离,跟 "cat" 和 "parliament" 的距离没有区别。任何两个不同的词都同样不相似。
N-gram 模型进一步加入了一点序列意识。它不再只问“当前词是什么”,而是问“给定前面 个词,下一个词通常是什么”。比如 trigram 会估计:
这对局部短语很有效,边界也很硬:窗口固定,表示离散而稀疏。某个组合很少出现,模型就没什么泛化空间;真正相关的信息在窗口外,模型也只能装作不知道。
我后来把这里记成一句话:
符号表示保留了身份,但没有保留语义距离。
词向量让意义有了几何
下一步是把离散身份变成连续表示。Bengio 的 neural language model,以及后来的 Word2Vec,让这个转变变得具体:一个词不再只是词表里的编号,而是从上下文里学出来的向量。
我们学习一个 embedding matrix:
其中第 行 就是词 的向量。出现在相似上下文中的词会靠得更近。于是我们得到了一种“意义的几何”:cosine similarity 开始有意义,类比关系变得可能,模型也能在没有人工规则的情况下共享统计信息。
这一步是一个真正的概念跳跃。语言不再只是字典查表,而变成了向量空间中的几何结构。
但静态 embedding 有个绕不开的问题:一个词类型只有一个向量。"bank" 在 "river bank" 和 "investment bank" 里含义不同,可是静态 embedding 在读句子之前就已经固定了。上下文确实在句子里,但词向量本身还没被上下文改写。
这一步解决了相似性,却留下了另一个问题:
连续向量解决了语义相似性,但静态向量无法完整表示依赖上下文的意义。
序列模型:开始有记忆,但路太长
RNN 开始处理上下文问题。它按顺序读取 token,并维护一个 hidden state:
这样,时间 的表示就不只取决于当前输入,还取决于之前读到的内容。模型不再孤立地看词,而是在边读边维护一个摘要。
LSTM 又进一步加入了门控记忆。模型不再盲目覆盖状态,而是学习什么时候写入,什么时候遗忘,什么时候暴露信息。这让“记忆”变得更可控。
但结构上它依然是串行的。第 80 个 token 想使用第 1 个 token 的信息,中间要经过很多 hidden state。训练时,梯度也要沿着这条链往回走。于是会出现两个实际问题:
- 长距离依赖很难稳定保留。
- 时间维度上的计算很难并行。
hidden state 很有用,但它像一条狭窄的走廊。上下文可以沿着它流动,可所有 token 都必须挤过同一条时间路径。
我觉得这就是 RNN 最微妙的地方:
Recurrence 让意义变得动态,但也让信息流变得串行而脆弱。
Seq2Seq 的瓶颈
Seq2Seq 模型把问题暴露得更清楚。做机器翻译时,encoder 读取源句子,把它压缩成一个 context vector;decoder 再从这个向量生成目标句子。
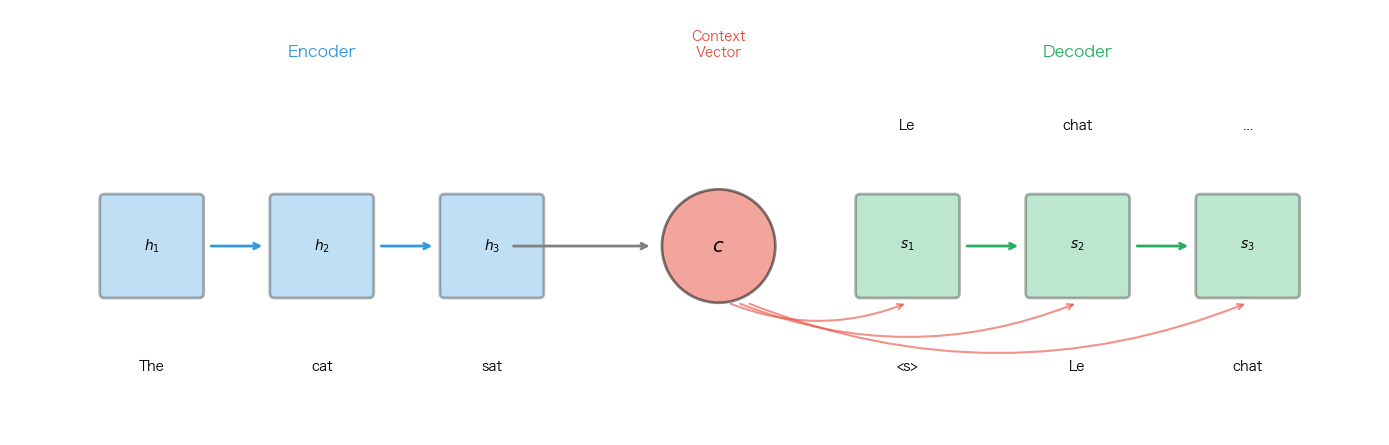
固定上下文的 encoder-decoder 模型要求一个向量总结整个源序列。
这个抽象很漂亮:
encoder 给 decoder 一个最终摘要 。decoder 在每一步生成时都使用同一个向量。
问题也很明显。短句可能还能塞进一个向量。长句里如果有性数一致、从句、代词指代、词序重排,把所有信息压进一个固定向量就不太合理。
想象翻译这句话:
The book is on the table because it is too slippery.
在某些目标语言里,"it" 可能需要跟 "book" 或 "table" 保持性别一致。decoder 在生成某个词时,应该能回头看具体哪个源词最重要。固定向量的问题在于,它要求模型在还不知道未来要用什么之前,先把所有东西一次性记住。
这不是 encoder 完全没学到东西,而是接口太窄:
瓶颈不在于 encoder 完全没有信息,而在于 decoder 不能选择性地取信息。
Attention:按需读取,而不是一次性记住
Attention 改变了 encoder 和 decoder 之间的接口。我们不再只给 decoder 最后的 hidden state,而是保留所有 encoder states:
在第 个 decoding step,decoder 计算 alignment score:
再归一化:
最后得到当前 step 专属的 context:
现在,每个输出 token 都有自己的 context vector。decoder 不再要求 encoder 把整句话压成一个摘要,而是问一个更具体的问题:
我现在要生成这个词,源句子里哪些位置最重要?

Soft attention 把翻译变成了可学习的 alignment。每个输出位置关注的源位置都可以不同。
这是我理解 Transformer 路线时的关键转折。Attention 经常被介绍成一个矩阵技巧,但它背后的想法更像“检索”:query 提出需求,key 决定匹配程度,value 提供被取走并混合的内容。
换句话说:
Attention 把一个全局记忆,替换成了很多次按需读取。
Self-attention:让 token 直接互相看
下一步其实很自然。如果 attention 可以让 decoder 读取 source sequence,那为什么不让同一个 sequence 里的 token 彼此读取?
这就是 self-attention。每个 token 产生 query、key、value:
序列通过比较所有位置之间的关系来更新自己:
真正重要的区别是结构性的。在 RNN 里,第 80 个 token 想拿到第 1 个 token 的信息,必须通过一串 hidden states。在 self-attention 里,第 80 个 token 可以在同一层里直接 attend 到第 1 个 token。
所以我更愿意把 self-attention 想成 token 之间的一张软图。这张图不是事先固定的,边权由当前表示动态算出来。代词可以看它指代的名词,动词可以看主语,图像 patch 可以看另一个 patch。模型不是先拿到一张依赖图再计算;它是在计算过程中把这张图软软地长出来。
这一点很关键:
Self-attention 让依赖建模变得直接、并行,并且依赖当前内容。
Transformer 不只是 attention
Transformer 不只是 self-attention。它是一套完整配方:
- Token embeddings 把离散输入变成向量。
- Positional encodings 注入顺序信息,因为 self-attention 本身对排列不敏感。
- Multi-head attention 让模型在多个学习到的关系空间中同时关注。
- Residual connections 和 layer normalization 让深层组合更容易训练。
- Feed-forward layers 在每个位置上局部变换已经上下文化的 token。
- Masking 控制生成时哪些位置可见。
- Encoder-decoder attention 让 decoder 读取已经编码好的 source states。
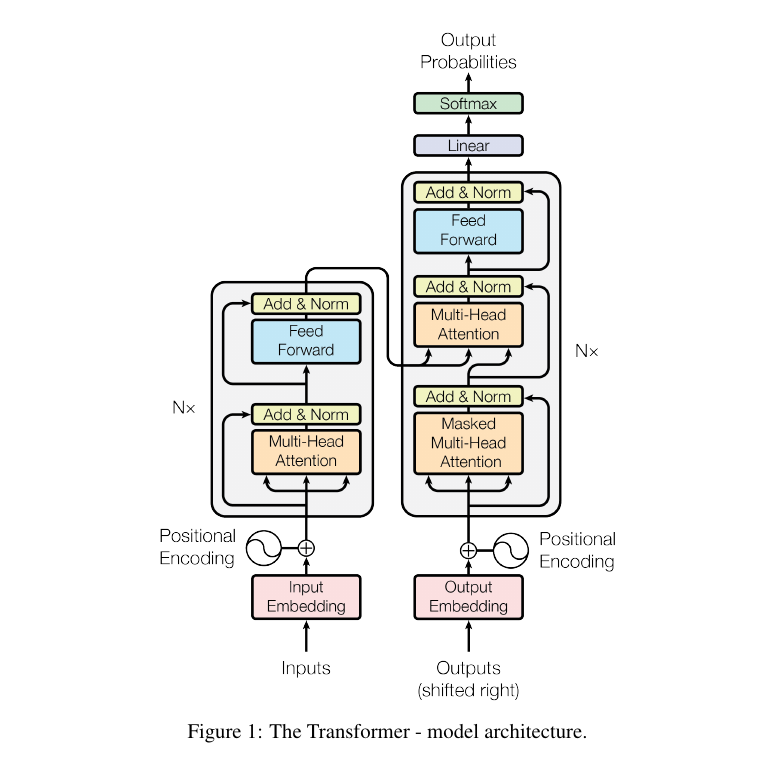
原始 Transformer 把 self-attention、cross-attention、位置信息、残差路径和局部 feed-forward 组合在一起。
Multi-head attention 这里很值得停一下。一个 attention head 可能只能抓住某一种关系。多个 head 可以分担任务:句法、指代、一致性、邻近上下文、长距离依赖、分隔符结构,或者任务相关的 alignment。我们当然不应该过度解释每一个 head,但架构上的想法很清楚:别把所有关系都挤进同一个 similarity function。
到这里,Transformer 就不再只是一个 NLP 技巧。它变成了一种通用方法:给定一组 token,通过学习到的 pairwise interaction 来更新它们。
到这里,我对 Transformer 的理解基本定型了:
一旦万物都能变成 token,attention 就成了通用的依赖建模引擎。
走出文本以后
slides 的最后一部分讨论的是:为什么 Transformer 会从机器翻译扩散到这么多领域?我的理解是,核心操作本来就不太依赖具体模态。
文本天然是 token 序列。图像可以切成 patches。音频可以切成 frames。视频可以表示成时空 patches。3D 场景可以表示成 views、points 或 latent tokens。只要输入变成了 tokens,同一个问题就会重新出现:
哪些 token 应该交互?交互强度是多少?
ViT 说明图像 patch 可以进入 Transformer encoder。CLIP 说明文本和图像可以对齐到同一个 embedding space。Diffusion 系统用 cross-attention 让文本 prompt 影响图像生成。Multimodal LLM 把视觉 token 投影到语言模型空间。视频和 3D 系统则把同样的模式扩展到时间和视角几何。
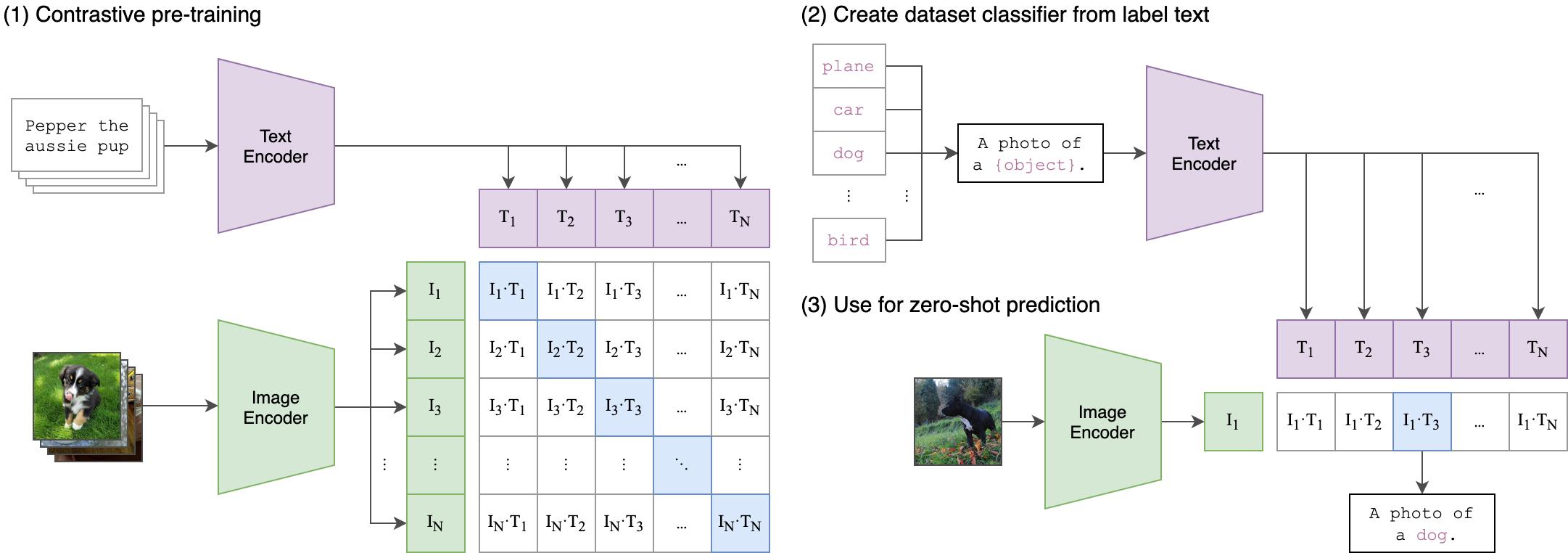
CLIP 把图文匹配变成几何问题:匹配的 pair 被拉近,不匹配的 pair 被推远。
重点不是“所有问题都变成语言”,而是很多问题都可以被表示成一组会相互作用的 tokens。
这也是我现在最愿意保留的总结:
Transformer 强大的原因,是它把通用操作和具体模态的前端分开了。Tokenization 会变,conditioning 会变,但 attention 这个原语保留下来。
我的总结
从词到注意力,并不是一条“模型越来越大”的直线,而是一串具体压力点的解决过程:
| 阶段 | 解决了什么 | 仍然痛在哪里 |
|---|---|---|
| One-hot | 精确身份标识 | 没有语义距离 |
| N-gram | 局部上下文 | 稀疏,窗口固定 |
| Embeddings | 语义几何 | 意义是静态的 |
| RNN/LSTM | 动态序列状态 | 长链脆弱,并行性差 |
| Seq2seq | 变长输入到变长输出 | 固定上下文瓶颈 |
| Attention | 动态检索 | 仍常和 recurrence 绑定 |
| Self-attention | 直接 token 交互 | 需要位置和架构配套 |
| Transformer | 可扩展依赖建模 | 序列变长时成本变高 |
所以我觉得,从历史路线理解 Transformer,比直接从公式理解更自然。公式很短,动机却是一步一步被逼出来的。
Transformer 并不神秘。softmax dot product 本身没有魔法,真正厉害的是它改变了模型内部默认的信息交流方式。信息不再沿着单一 recurrent thread 传递,而是让每个 token 主动询问整个上下文中什么最相关。
一旦理解了这一点,后面的 ViT、CLIP、diffusion、multimodal LLM、video model 就不再像彼此无关的发明。它们其实是在反复使用同一个设计原则:
把世界变成 tokens,然后学习 tokens 之间的依赖结构。
参考
- Yoshua Bengio et al. (2003), A Neural Probabilistic Language Model.
- Tomas Mikolov et al. (2013), Efficient Estimation of Word Representations in Vector Space.
- Kyunghyun Cho et al. (2014), Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation.
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio (2015), Neural Machine Translation by Jointly Learning to Align and Translate.
- Ashish Vaswani et al. (2017), Attention Is All You Need.
- Alexey Dosovitskiy et al. (2021), An Image is Worth 16x16 Words.
- Alec Radford et al. (2021), Learning Transferable Visual Models From Natural Language Supervision.